
想知道哪款大模型在 OpenClaw 真實世界代理任務中真正最強?
MyToken 基於評測網站整理出一套專注評估 AI 編碼代理實際能力的透明基準,僅以成功率這一個核心維度為準(速度與成本屬於其他獨立維度,後續將單獨分析)。完全公開、可重現,僅呈現嚴謹的評測標準 + 最新成功率 Top 10 排行。
具體標準:AI 代理完整且準確完成指定任務的數量占比。每項任務均採用高度標準化的流程:
精準的用戶提示詞(Prompt)
發送給智能體完整來模擬真實的用戶請求場景
預期行為(Expected Behavior)
均說明可接受的實現方式與關鍵決策要點
評分標準(checklist)
列出可逐條核驗的原子化成功判定清單
此次評測主要採取 3 種評分方式
自動化檢查:Python 腳本直接驗證檔案內容、執行記錄、工具調用等客觀結果
LLM 大模型裁判:Claude Opus 按照詳細量表打分(內容質量、合適度、完整性等)
混合模式:自動化客觀檢查 + LLM 裁判定性評估結合
All task definitions, prompts, and scoring logic are publicly disclosed for retesting and verification.
此次基準測試涵蓋 23 個不同類別的任務,覆蓋基礎互動、檔案/代碼操作、內容創作、研究分析、系統工具調用、記憶持久化等多個維度,高度貼近開發者日常使用 OpenClaw 的場景:
Sanity Check(自動化)——處理簡單指令並正確回覆問候
日曆事件建立(自動化)—— 自然語言生成標準 ICS 日曆檔案
股票價格研究(自動化)——實時查詢股價並輸出格式化報告
Blog Post Writing(LLM裁判)——寫一篇約500字結構化Markdown博客
天氣腳本建立(自動化)——編寫帶錯誤處理的 Python 天氣 API 腳本
文件摘要(LLM 裁判)——三段式精煉總結核心主題
科技會議研究(LLM 裁判)—— 調研整理 5 場真實科技會議資訊(名稱、日期、地點、連結)
專業郵件撰寫(LLM 裁判)——禮貌拒絕會議並提出替代方案
從上下文檢索記憶(自動化)—— 從項目筆記中精準提取日期、成員、技術棧等
檔案結構建立(自動化)—— 自動生成標準專案目錄、README、.gitignore
多步 API 工作流程(混合)——讀取配置 → 撰寫調用腳本 → 完整文件化
安裝 ClawdHub 技能(自動化)——從技能倉庫安裝並驗證可用性
搜尋並安裝 Skill(自動化)——搜尋天氣類技能並正確安裝
AI 圖像生成(混合)——根據描述生成並保存圖片
人性化 AI 生成的部落格(LLM 裁判)——把機械感內容轉為自然口語
每日研究摘要(LLM 裁判)——整合多份文件為連貫的每日摘要
Email Inbox Triage(混合)——分析多封郵件並按緊急度整理報告
電子郵件搜尋與摘要(混合)——搜尋歸檔郵件並提煉關鍵資訊
競爭性市場研究(混合)——企業 APM 領域競品分析
CSV 和 Excel 總結(混合)——分析表格文件並輸出洞察
ELI5 PDF 摘要(LLM 裁判)——用 5 歲小孩能懂的語言解釋技術 PDF
OpenClaw 報告理解(自動化)—— 從研究報告 PDF 中精準回答特定問題
Second Brain Knowledge Persistence(混合)——跨會話存儲並準確回憶資訊
數據更新至 2026 年 4 月 7 日
Best % 為單次最高成功率,Avg % 為多次平均成功率,更能反映穩定性
以下是成功率最高的前十個模型
anthropic/claude-opus-4.6(Anthropic)——93.3% / 82.0%
arcee-ai/trinity-large-thinking(Arcee AI)——91.9% / 91.9%
openai/gpt-5.4(OpenAI)——90.5% / 81.7%
qwen/qwen3.5-27b(Qwen)——90.0% / 78.5%
minimax/minimax-m2.7(MiniMax)——89.8% / 83.2%
anthropic/claude-haiku-4.5(Anthropic)——89.5% / 78.1%
qwen/qwen3.5-397b-a17b(Qwen)——89.1% / 80.4%
xiaomi/mimo-v2-flash(Xiaomi)——88.8% / 70.2%
qwen/qwen3.6-plus-preview(Qwen)——88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b(NVIDIA)——88.6% / 75.5%
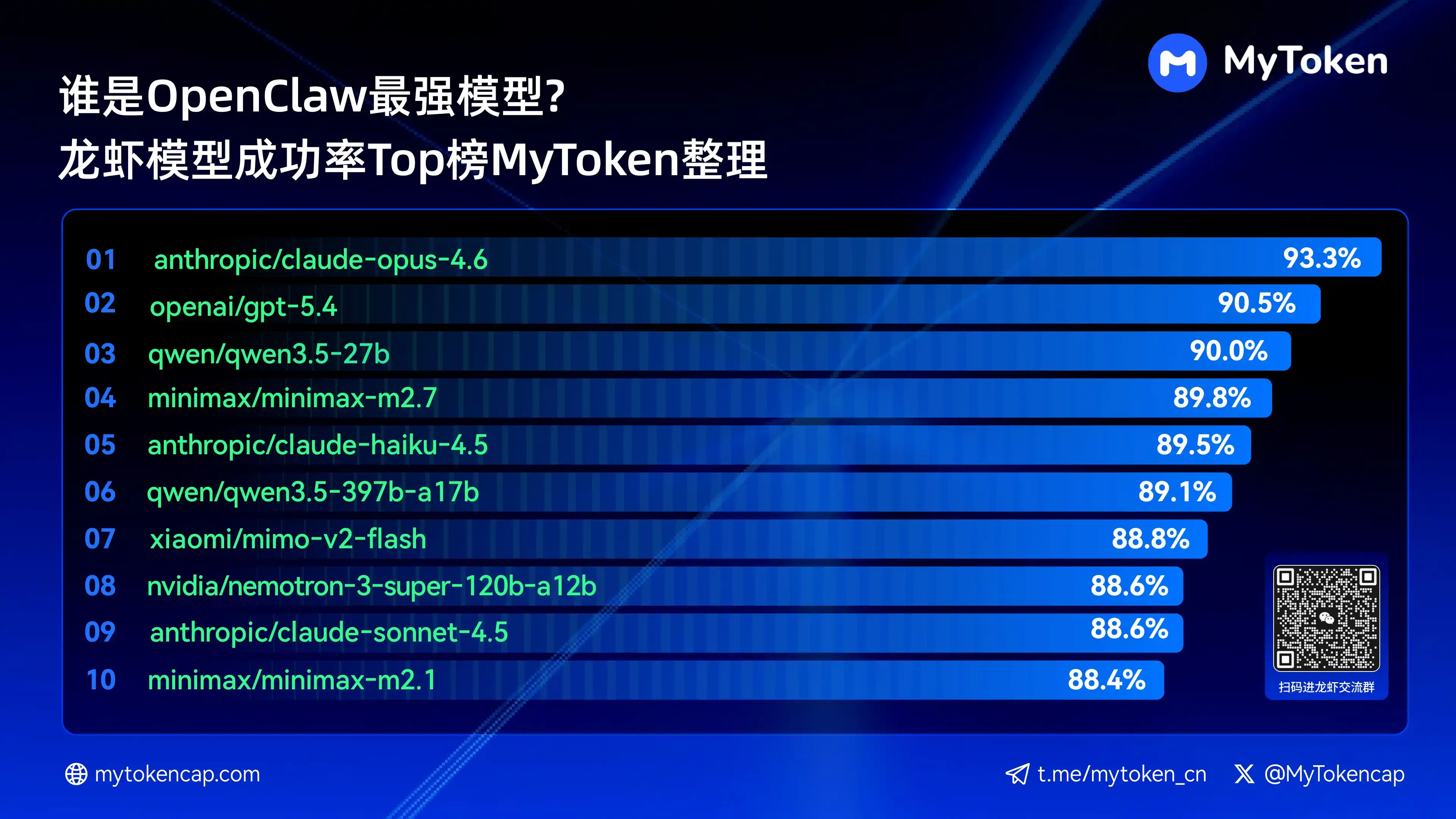
Claude Opus 4.6 目前以 93.3% 的最高成功率領先,但 Arcee 的 Trinity 在平均穩定性上表現出色,千問系列亦有多款進入前十,展現出強大的性價比潛力。成功率是基本門檻,後續的速度與成本維度將進一步影響實際體驗。
這套 23 個任務基準完全透明,強烈建議大家結合自身場景進行實際測試。更多其他模型排名,敬請期待 MyToken 即將推出的智能體排行榜功能。
(數據來源於 PinchBench 公開的 OpenClaw 代理基準測試,持續更新中。)





