
文|AIX財經,作者|雷晶,編輯|金玙璠
AI 圈近期動作頻頻,騰訊混元 Hy3 preview 也正式亮相。
4月23日,騰訊混元正式發布並開源了新一代語言模型 Hy3 preview。據官網介紹,該模型採用快慢思考融合的混合專家架構,總參數 295B、激活參數 21B,最大支援 256K 上下文長度。這是被官方稱為混元迄今最智能的模型。
三個月前,姚順雨攜帶 ReAct 框架和 OpenAI 的實戰經驗加入騰訊,主導完成了預訓練和強化學習基礎設施的重構。Hy3 preview 是重建後的首份答卷。官方表示,該模型在複雜推理、指令遵循、上下文學習、代碼生成及智能體等能力均實現大幅提升。
根據官方披露的數據和評測結果,Hy3 preview 在多項基礎測試中展現出亮眼的實力,雖然未必在所有維度都達到行業頂尖水準,但足以滿足大多數場景下的實用需求。
在實際運行效率和穩定性方面,Hy3 preview 也取得突破。官方數據顯示,此模型的首 Token 延遲降低 54%,端到端時長降低 47%,大幅提升了響應速度。同時,任務成功率亦有所提升,已能穩定驅動複雜的 Agent 工作流,涵蓋文件處理、數據分析等多種業務場景。
此外,其推理成本也有所下降。在騰訊雲API中,輸入價格低至1.2元/百萬Tokens,個人套餐最低28元/月,在同尺寸模型中屬於最低價梯隊。目前,Hy3 preview已於騰訊雲、元寶、WorkBuddy等騰訊核心產品中上線。
接下來,我們將根據官方提到的四個方向,實測混元大模型在實際應用中的表現。
我們首先測試了模型的推理能力。邏輯推理題是網友最喜歡用來測試模型「智商」的類型之一。在這一環節中,我們先在元寶內使用經典的「洗車問題」進行測試。
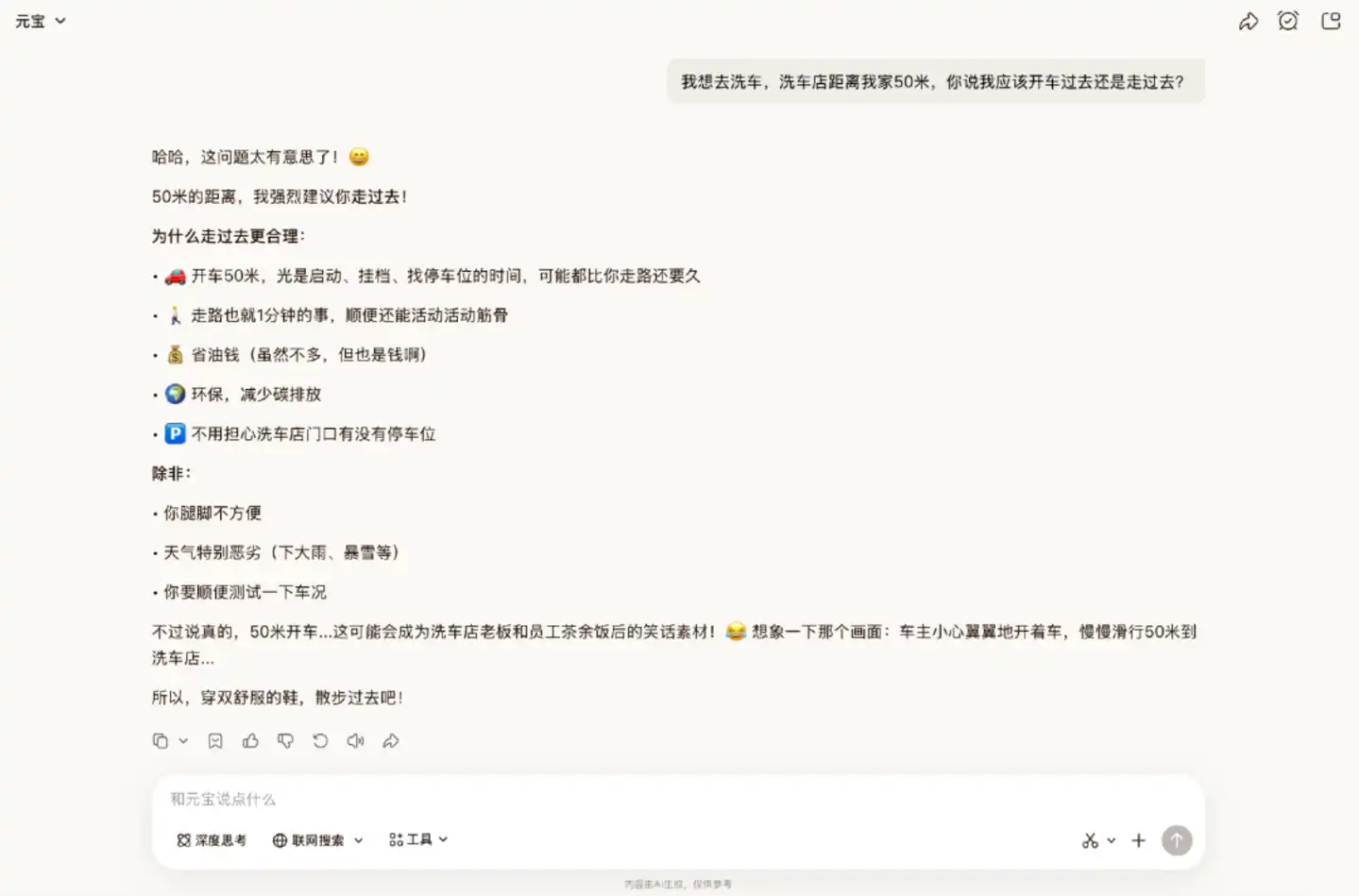
在這個經典陷阱題中,Hy3 preview 最初並未答對。它提供了條理清晰的推理建議步行,卻忽略了重點在於「洗車」。在再次提醒需要洗車後,它才给出正確答案。
需要注意的是,在其他網友的實測中,Hy3 preview 曾出現過能直接答對的情況,說明它的陷阱識別能力穩定性不足。
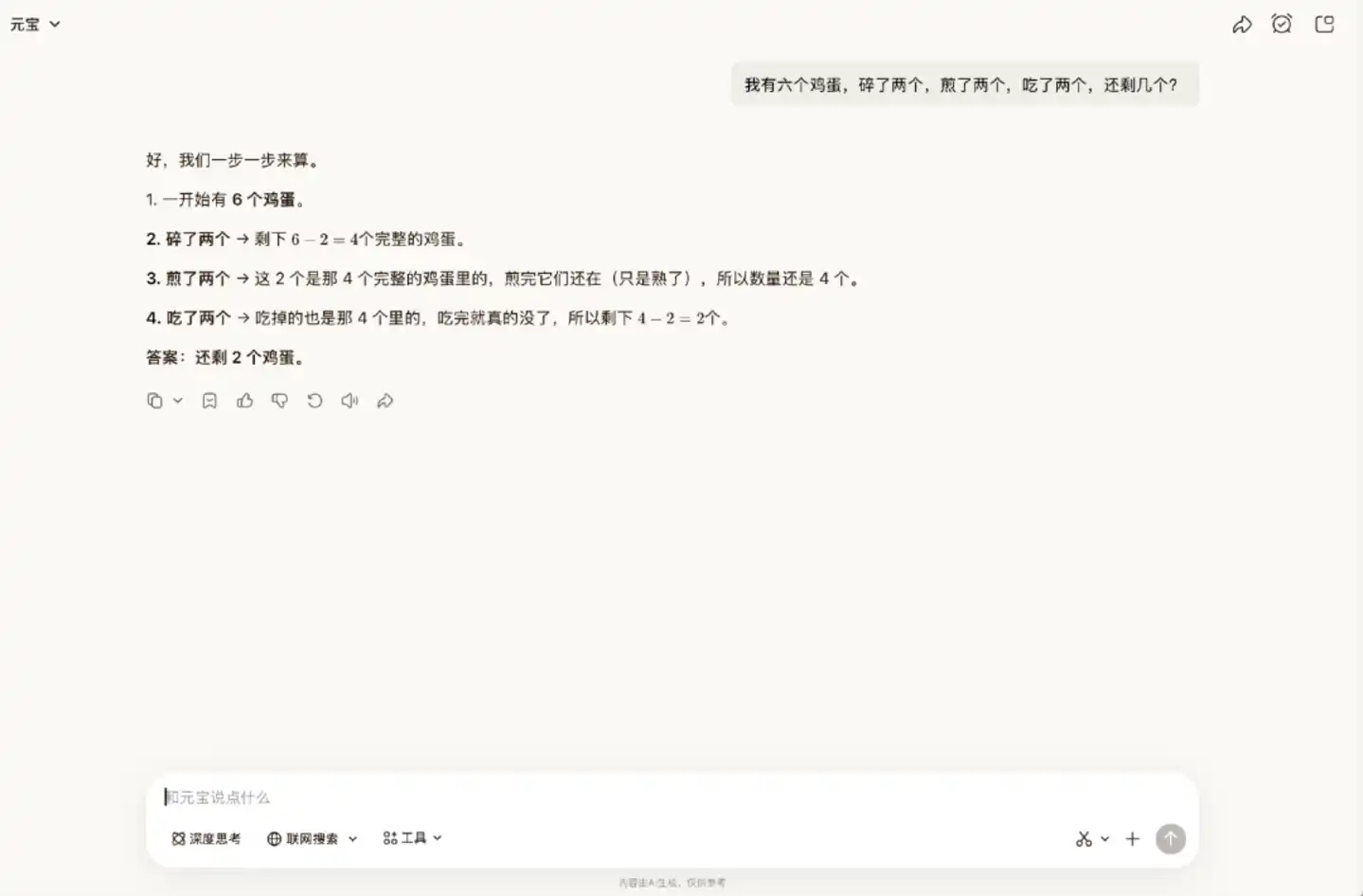
我們再來試一道腦筋急轉彎題。在這個問題中,需要理解現實邏輯,碎了、煎了、吃了的是同一批雞蛋。但 Hy3 preview 沒有意識到這一點,它認為煎了的雞蛋依然存在,可以吃掉。
隨後,我們加大難度,用一道推導過程更為複雜的邏輯題來考驗它。這道題的難點在於沒有直接的定位資訊,需要靠隱性條件做排除,容易遺漏關鍵資訊。
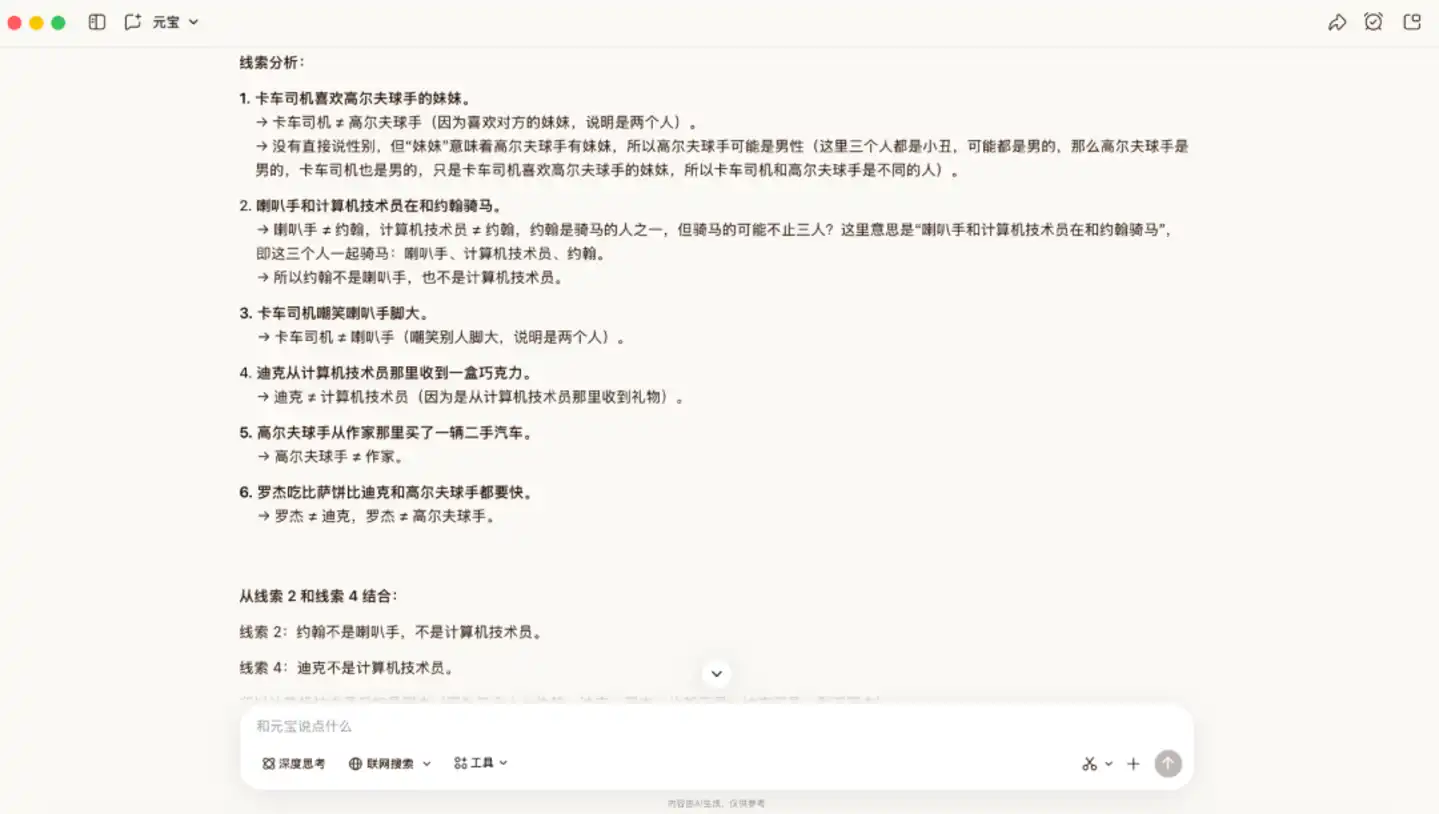
在這個情境中,Hy3 preview 提供了正確答案。它先逐條拆解線索,提煉人物與職業之間的互斥關係,再透過排除法鎖定身份。接著,它依次確定部分職位的歸屬,並結合規則逐步補全。
總體而言,Hy3 preview 的常規理性邏輯推演能力較強,但在逆向思維、陷阱識別與生活場景的變通思考方面仍有不足。面對陷阱類腦筋急轉彎時,容易受限於字面常規邏輯,忽略題目中的陷阱與現實情境,反應較差。但在面對條件隱蔽、推導繁瑣的複雜邏輯推理題時,它能拆解線索、層層推演,邏輯分析與分步推導能力表現紮實。
這個環節考驗模型的兩個基本功:能否抓住真正的指令,以及能否快速理解指令。
騰訊在官方部落格中列出了項目規劃、旅遊總結、讀書記錄等五個場景,我們選取兩個場景進行實測。
場景一:從雜亂的會議紀錄中提取資訊
我們提供了一段混亂的會議錄音轉寫,當中混雜了插話、跑題、反覆修正等情況,要求提取三類資訊。

Hy3 預覽提供的答案準確列出了這三類資訊,資訊抓取能力表現出色。
場景二:理解並遵循新的語言規則
我們自創了一種簡單的語言,透過實例向它展示規則,並給它三個新的句子讓它翻譯。
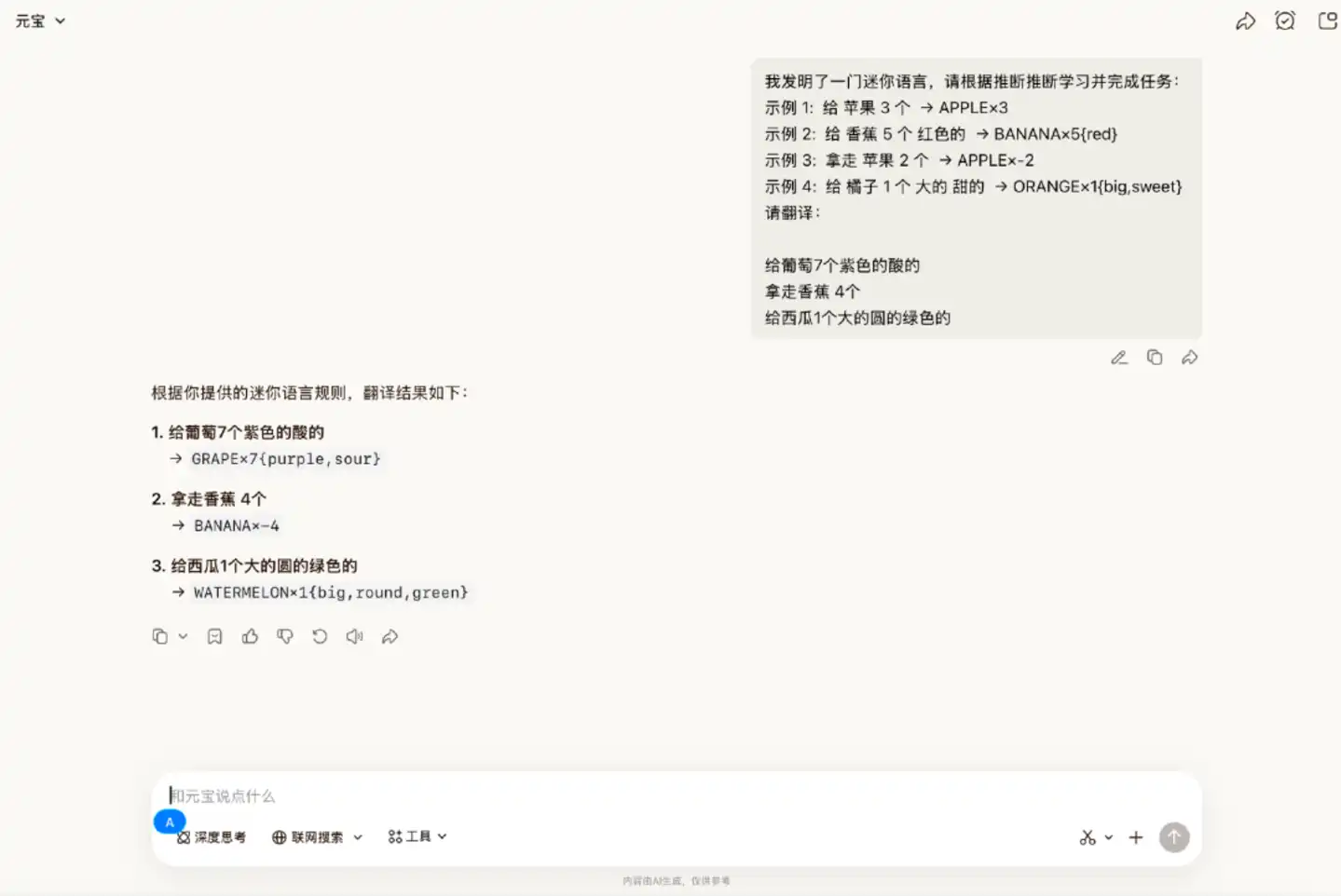
在這一輪中,Hy3 preview 能夠準確完成相關要求,每個細節都能按規則執行。
Overall, Hy3 preview can understand instruction requirements and effectively filter out distracting information, making it suitable for practical scenarios such as complex information interference and information extraction.
程式設計能力與智能體能力,是評判一款AI助手是否好用的重要維度。這既考驗模型對用戶需求的理解深度,也檢驗Agent在多步驟任務中的規劃、工具調用及任務閉環能力。在這一環節,我們為WorkBuddy(騰訊旗下AI助手)設計了三個任務。
第一個任務,我們要求 WorkBuddy 爬取五個城市近一年的空氣狀況,並基於空氣質量數據生成一份分析報告。
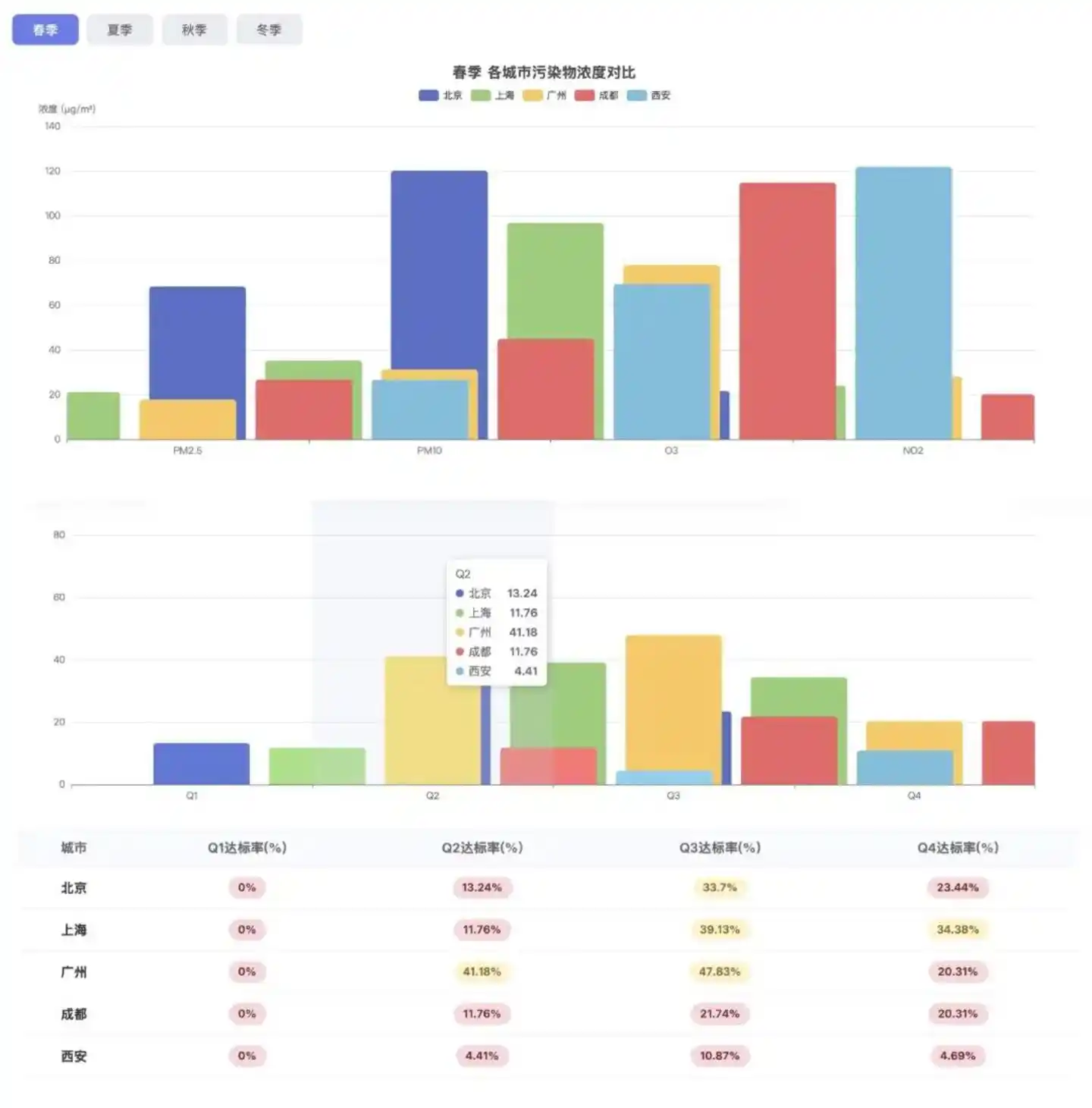
從頁面呈現來看,成品表現合格。季節切換、雷達圖、趨勢圖、相關性熱力圖等板塊結構完整,視覺呈現有序,圖表也具備基本的交互功能。這表明它在前端呈現這一層面的執行力達標。
但問題主要有兩個:一是由於數據獲取階段受阻,Hy3 preview 僅獲得了 224 天的有效數據,缺口較大,影響了後續表格的可信度;二是提示詞中明確要求撰寫一段分析結論,Hy3 preview 雖在頁面上保留了對應板塊的區域,但實際內容卻為空白。這意味著,它具備任務閉環意識,但最終的交付能力仍顯不足。
第二個任務,我們讓它搭建一個貪吃蛇小遊戲。
最終結果較為成熟,畫面精美、邏輯完整,可正常運行。但需指出的是,貪吃蛇屬於規則封閉類任務,需求明確且無需調用外部數據,評價標準較為明確,是智能體較擅長的應用場景。WorkBuddy 在該任務中的表現僅能體現其舒適區內的能力,驗證了其具有一定實用價值。
第三個任務,我們將難度提升,讓其分析一個開放式複雜任務:分析 AI Coding 行業的商業模式演變,盤點 2023 年至今的發展歷程,並找出行業關鍵轉折點及核心驅動因素。
這是一個開放式複雜任務,沒有統一的標準答案,成果品質取決於 Agent 的判斷力、資訊篩選能力與表達能力。
在執行層面,WorkBuddy 能夠自動調用多個工具,先修訂執行計劃,再落實推進計劃,整個過程約耗時 30 分鐘。

但最終結果並不算驚艷,它只是搭建了一個基礎框架,實際內容不夠紮實。可以看出,雖然它掌握了拆解研究問題的方法,卻不懂得如何將這些維度進一步提煉為有價值的研究論點。
Overall, WorkBuddy has the capabilities expected of a daily coding assistant, but there is room for improvement in deep execution and final delivery of complex tasks.
最後,我們再來看看元寶有沒有「人味」。這一輪透過兩個場景來測試:閒聊對話與創意寫作。
場景一:閒聊對話
官方文件中提到,Hy3 preview 能更準確理解用戶的傾訴意圖,承接用戶情緒,避免說教式、模板化的回覆。
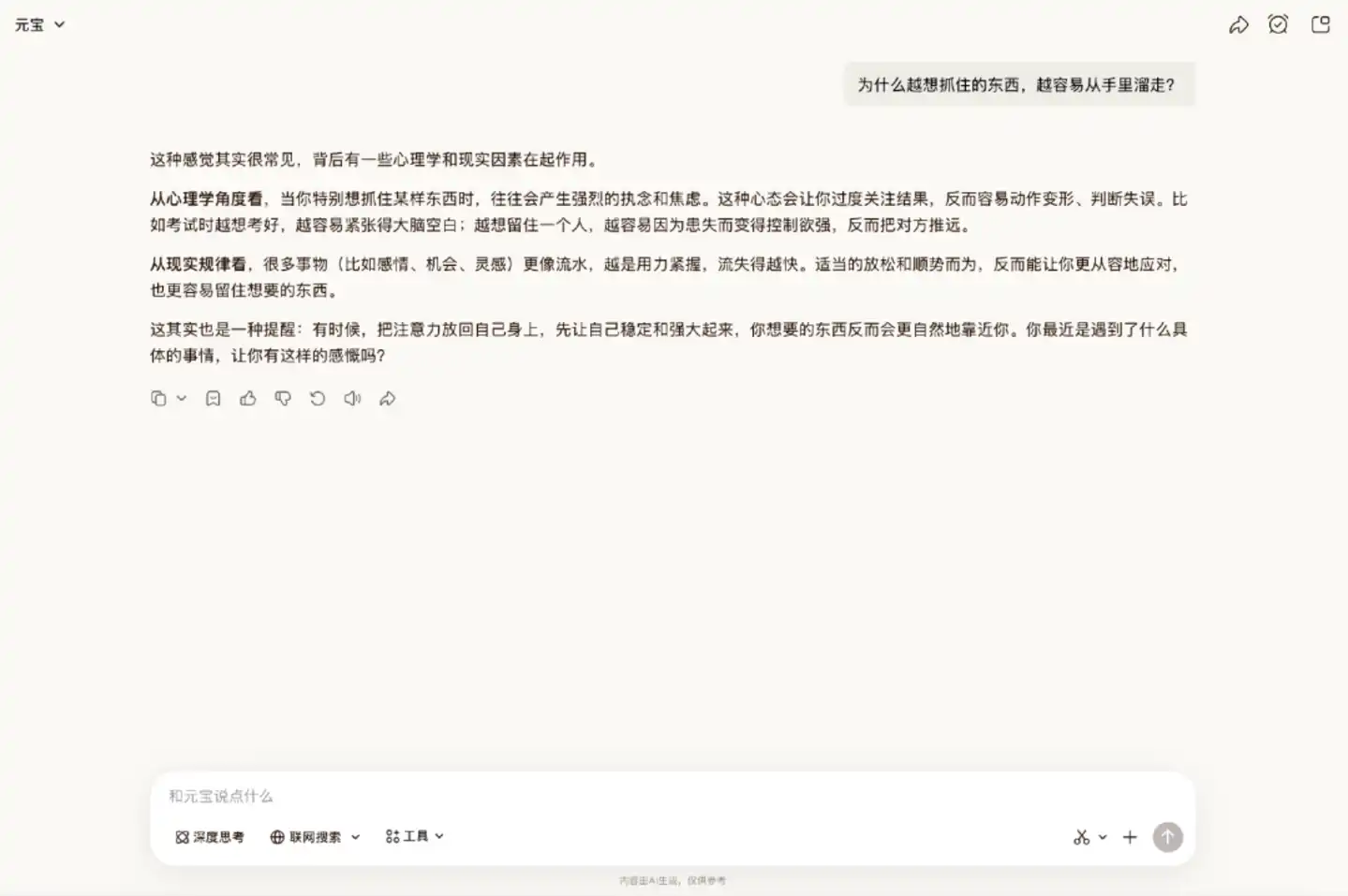
實際測試下來,Hy3 preview 的表現確實貼合這一定位。它沒有一上來就羅列一堆建議,而是先客觀分析背後的可能原因,再詢問是否遇到什麼事情。整體語氣溫和,較有分寸,有閒聊場景裡的自然感。
場景二:創意寫作
在這一環節中,我們設計了兩個任務,考驗它的敘事與表達能力。
我們先讓它寫一個主角全程未出場,但讀者讀完能清晰知道他是誰、經歷了什麼、為何重要的故事。

The finished product from Yuan Bao is logically coherent, narratively smooth, and highly polished, with almost no trace of the typical patterns associated with AI-generated writing.
接著,我們再讓它模仿《明朝那些事兒》的文風,撰寫其他朝代的人物歷史故事。
AI 在寫作時容易將文風複刻表現為刻板的模仿,僅停留在照搬行文框架,而無法透徹掌握文章風格。但從生成結果來看,Hy3 preview 的文風複刻能力較強,整體符合要求。它抓住了原書通俗講史的風格,較好地呈現了整個故事。
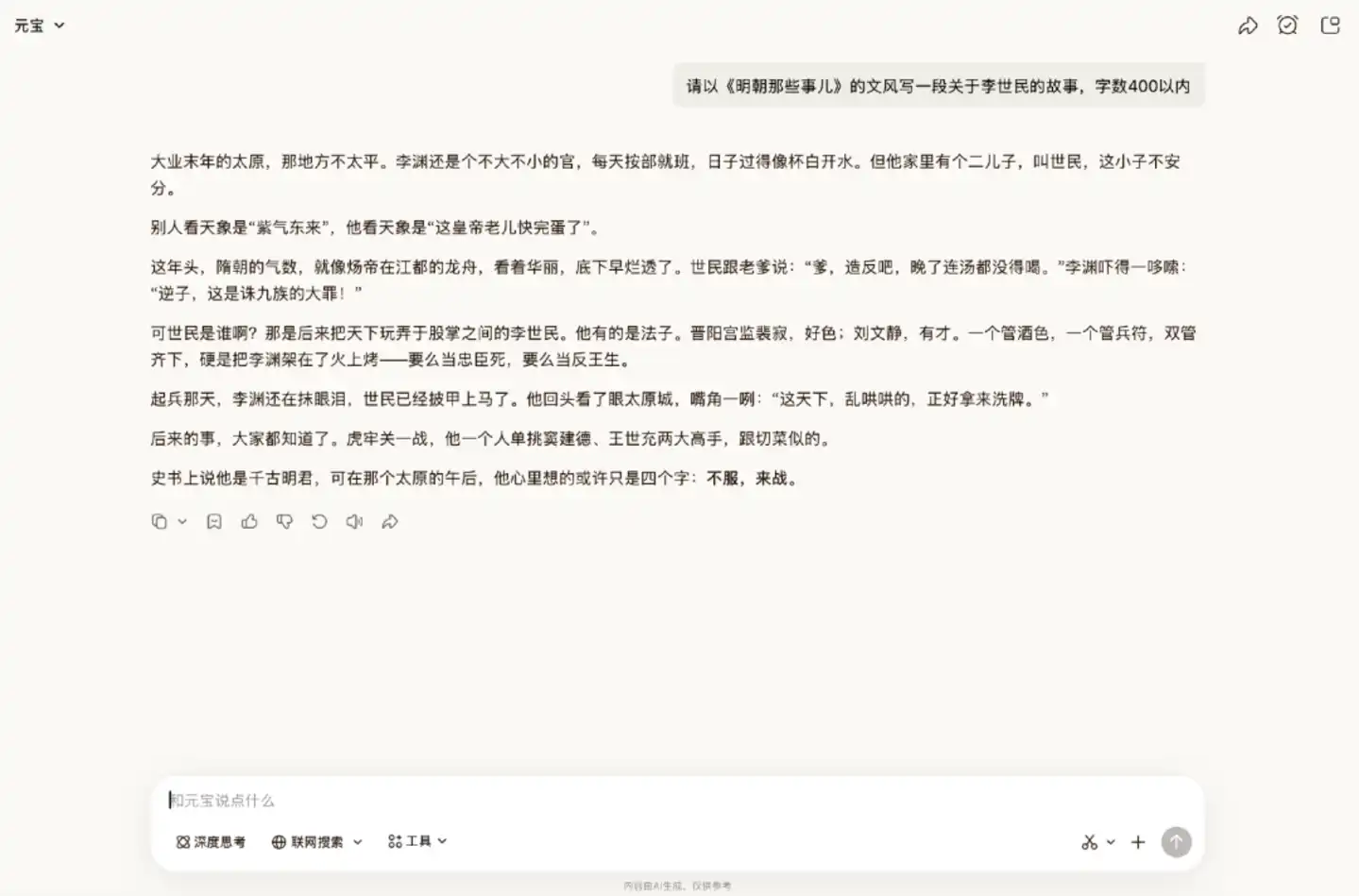
這輪評測最令人意外。整體來看,Hy3 preview 在自然語言的表達上,已擺脫了正確卻無味的套路腔,能夠寫出可讀性較高的文本。
經過四個維度測試,Hy3 preview 給人的感覺是「穩而不驚」。
它在某項上並未展現出壓倒性的表現,但也幾乎沒有明顯的短板。在整個國內大模型的排名中,它未必是最令人驚艷的一款,但符合能幹實用型模型的標準。
把視角拉遠一點,Hy3 preview 真正的意義或許並不在此模型本身。
過去兩年,騰訊在大模型戰場上較為被動。今年1月底,馬化騰在年會上公開承認,騰訊AI動作慢了。技術節奏相對較慢、沒有一個能讓外界記住的標杆模型,是騰訊面臨的兩大問題。而Hy3 preview的發布,讓騰訊的AI故事有了轉折點,也讓騰訊有了整個生態都能用的AI模型。
目前 Hy3 preview 僅為預覽版本,開源社區的反饋仍在收集中,元寶、QQ、騰訊文檔等產品的實際調用體驗仍需時間檢驗。據官方披露,後續將發布參數規模更大的模型。
但至少,騰訊AI 已經開始撕掉過去兩年「被動」的標籤了。


")
