
作者:克洛德,深潮 TechFlow
深潮導讀:英偉達於 4 月 14 日「世界量子日」發布全球首個開源量子 AI 模型家族 Ising,糾錯解碼速度較行業標準提升 2.5 倍、精度提升 3 倍。
量子概念股當日集體暴漲,IonQ 漲 18%、D-Wave 漲 15%。同日,首席科學家 William Dally 在 GTC 2026 上透露,AI 已將晶片標準單元庫移植從 8 人 10 個月壓縮至一塊 GPU 一夜完成,且設計結果優於人工。
英偉達正利用 AI 加速兩個最困難的工程問題:讓量子電腦真正可用,以及讓 GPU 設計本身更快更好。
4 月 14 日「世界量子日」,英偉達發布了全球首個面向量子計算的開源 AI 模型家族 NVIDIA Ising,量子概念股應聲集體上漲。同期,公司首席科學家 William Dally 在 GTC 2026 上披露了 AI 在英偉達內部晶片設計流程中的最新進展,其中一項任務的效率提升幅度達到數百倍量級。
兩條線索指向同一個判斷:AI 正從「應用層工具」轉變為「基礎設施的基礎設施」,既加速下游產業(量子計算),也加速 AI 自身的硬體迭代。
全球首個開源量子 AI 模型,瞄準量子計算兩大瓶頸
根據英偉達 4 月 14 日的新聞稿,Ising 模型家族首批包含兩個模型領域:Ising Calibration 和 Ising Decoding,分別針對量子計算落地的兩大核心瓶頸。
量子處理器的量子位元(qubit)天生具有噪聲,目前最優秀的量子處理器大約每千次運算會出現一次錯誤。要讓量子電腦具備實用價值,錯誤率需降至兆分之一以下。
Ising Calibration 是一個 350 億參數的視覺語言模型,能自動解讀量子處理器的測量數據並做出校準決策,將此前需要數天的校準流程縮短至數小時。Ising Decoding 則是一對 3D 卷積神經網絡模型(分別優化速度和精度),用於量子糾錯的實時解碼,較當前開源行業標準 pyMatching 快 2.5 倍、精度高 3 倍。
英偉達量子產品總監 Sam Stanwyck 在發布會上解釋了開源策略的邏輯:量子硬體廠商各自的噪聲特徵不同,開源模型允許他們在本地使用自有資料進行微調,既提升性能又保護專有資料。
NVIDIA 執行長黃仁勳的表態更為直接。他在聲明中表示,AI 正在成為量子機器的控制平面,將脆弱的量子位元轉化為可擴展、可靠的量子 GPU 系統。
根據英偉達披露,已有多家機構率先採用 Ising 模型,包括哈佛大學工程與應用科學學院、費米國家加速器實驗室、IQM Quantum Computers、勞倫斯伯克利國家實驗室、英國國家物理實驗室等。
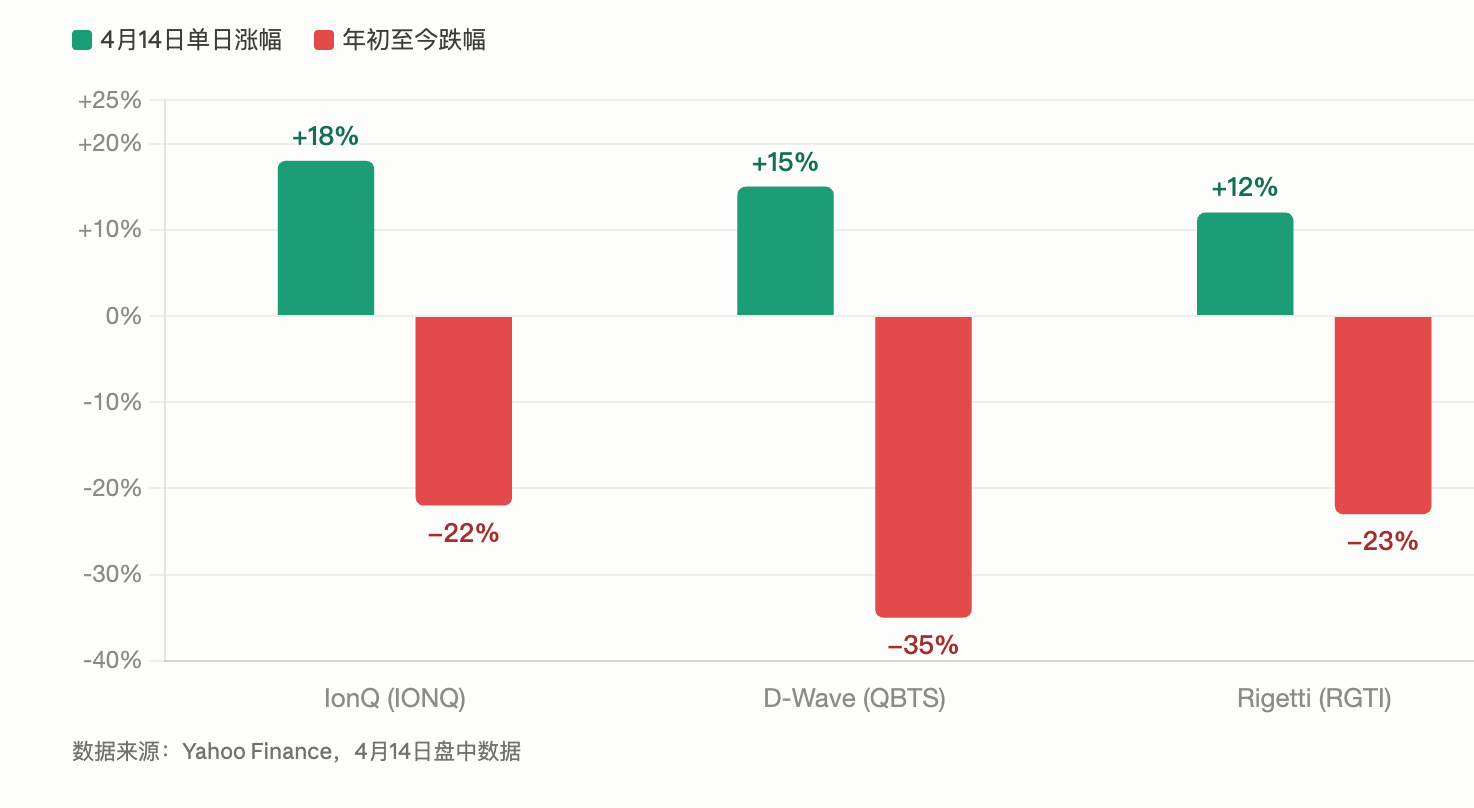
量子概念股集體暴漲,IonQ 單日飙升 18%
Ising 發布當天,美股量子概念股出現一輪集體暴漲。據 Yahoo Finance 數據,IonQ 當日上漲約 18%、D-Wave Quantum 涨約 15%、Rigetti Computing 涨約 12%。
此輪漲幅的背景是量子概念股自年初以來普遍處於深度回調。截至 4 月 14 日,IonQ 年內下跌約 22%,D-Wave 下跌約 35%,Rigetti 下跌約 23%。當日的雙位數反彈並未改變年內下行趨勢,但集體聯動的幅度仍令人矚目。
需要指出的是,這輪行情的驅動因素並非僅有 Ising 發布。IonQ 同日宣布了量子網絡里程碑進展和一份 DARPA 合同,Rigetti 也有來自印度高級計算發展中心(C-DAC)的 840 萬美元訂單消息。多重催化劑疊加放大了板塊效應。
分析機構 Resonance 預測,全球量子計算市場規模到 2030 年將超過 110 億美元。量子經濟發展聯盟(QED-C)在同日發布的報告中稱,2025 年全球量子市場已達 19 億美元,純量子企業員工增長 14%。
80 人月壓縮至一夜:AI 重塑英偉達晶片設計流程
Ising 指向外部產業加速,英偉達內部則用 AI 重塑自身的晶片設計流程。
英偉達首席科學家 William Dally 在 GTC 2026 與谷歌首席科學家 Jeff Dean 的對談中,披露了多個具體案例。最具衝擊力的數據來自標準單元庫移植:每當英偉達轉向新的半導體製程(例如從 7 納米到 5 納米),需要重新設計適配新工藝的約 2500 至 3000 個標準單元,此前需 8 名工程師耗時約 10 個月。英偉達開發了一套名為 NVCell 的強化學習工具,如今可在一塊 GPU 上一夜完成,且產出的單元在面積、功耗和延遲等指標上匹配甚至優於人工設計。
根據 Tom's Hardware 報導,Dally 將這個過程形容為一個「修復設計規則錯誤的電子遊戲」,強化學習正擅長此類試錯式優化。
在更高的抽象層面,英偉達開發了內部專用大語言模型 Chip Nemo 和 Bug Nemo。這些模型基於英偉達 30 年累積的專有數據進行微調,涵蓋了公司歷史上所有 GPU 的 RTL 代碼、硬體設計文檔和架構規格。據 Dally 介紹,初級工程師可直接向 Chip Nemo 提問,省去反覆打擾資深設計師的時間。他將 Chip Nemo 描述為「一個非常有耐心的導師」。
在電路優化層面,英偉達還將強化學習應用於進位前瞻鏈等經典電路設計問題。Dally 表示,AI 產出的設計方案「完全是人類不會想到的怪異方案,但實際性能比人類設計好 20% 到 30%」。
Still a long way to go before AI can independently design chips
不過 Dally 也明確劃定了預期邊界。他說,自己很想實現端到端的狀態,目前離那個目標還很遠。
NVIDIA 目前的 AI 芯片設計仍為輔助而非替代。AI 在標準單元移植、Bug 分類與摘要、佈局布線預測、架構空間探索等環節各自發力,但尚未形成完整的端到端自動化流程。Dally 設想的長期方向是多智能體模型,不同的 AI 系統各自負責設計的不同環節,類似人類工程團隊的分工方式。
根據 Computer Weekly 報導,Dally 和 Dean 在對談中還討論了 AI 智能體對傳統軟體工具的衝擊:當 AI 智能體的運行速度遠快於人類時,為人類用戶設計的傳統軟體工具將成為性能瓶頸,從程式設計工具到業務應用都需要重新設計。



