
編者按:許多人在使用 Claude Code 時,最直觀的感受是 Token 消耗太快,長會話很容易耗盡配額。但從 Anthropic 工程師的視角來看,真正影響成本的,往往不是你寫了多少代碼,而是系統是否持續複用已處理的上下文。
本文分享的核心,就是如何通過緩存機制節省 Token。作者一週內通過緩存複用了超過 3 億 Token,單日緩存量達到 9100 萬。由於緩存 Token 的成本只有普通輸入 Token 的 10%,這意味著 9100 萬緩存 Token 實際計費約等於 900 萬普通 Token。Claude Code 長會話之所以顯得更「耐用」,不是因為模型免費工作,而是大量重複上下文被成功複用了。
Prompt caching 的關鍵在於「不要打斷緩存」。Claude Code 會將系統提示、工具定義、CLAUDE.md、項目規則和歷史對話分層緩存;只要後續請求的前綴保持一致,Claude 就可以直接讀取緩存,而不是重新處理整段上下文。Anthropic 內部也會監控 prompt cache 的複用率,因為它不僅影響用戶額度,也直接關係到模型服務成本和運行效率。
對於普通用戶來說,不必理解所有底層細節,只需要掌握幾個關鍵習慣:不要讓會話空置超過 1 小時;切換任務時做好 session handoff;避免頻繁切換模型;大文件盡量放進 Projects,而不是反覆貼進對話。
這篇文章与其說是在講一個省 Token 技巧,不如說是在提供一套更接近工程師思維的 Claude Code 使用方法:把上下文當作資產管理,讓快取持續複用,讓長會話少做重複計算。
以下為原文:
我這週省下了 3 億 Token,單日 9100 萬,一週超過 3 億。
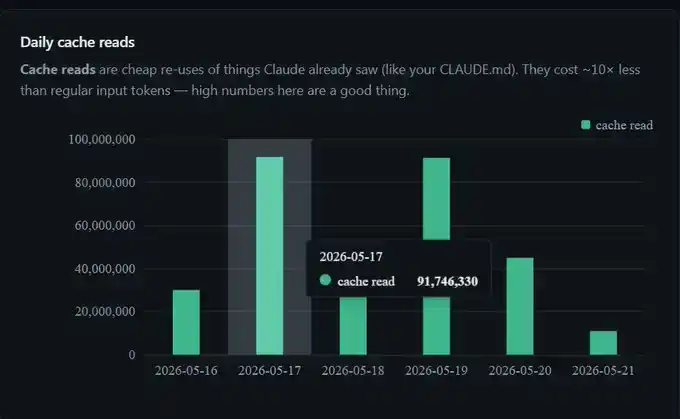
我沒有更改任何設定。這只是 prompt caching 在後台正常運作。
但當我真正理解了快取是什麼,以及如何避免「打斷」快取之後,在同樣的使用配額下,我的會話可以持續更久。因此,這裡整理一份 Claude Code 快取的 80/20 入門指南,不涉及 API 層面的深度細節。
緩存 Token 的成本僅為普通輸入 Token 的 10%。9100 萬緩存 Token,實際計費約相當於 900 萬 Token。
Claude Code 訂閱版的快取 TTL 是 1 小時;API 預設是 5 分鐘;Sub-agent 永遠是 5 分鐘。
快取分為三層:系統層、項目層、對話層。
在會話中途切換模型會破壞快取,包括啟用「opus plan」模式。
Each cached token costs 10% of a regular input token.

所以,當我的儀表板顯示某一天有 9100 萬 Token 命中了緩存時,實際計費大概只相當於處理了 900 萬 Token。這也是為什麼和沒有緩存相比,長時間使用 Claude Code 時,會讓人感覺會話幾乎是「免費」延長的。
儀表板上有兩個數字值得重点关注:
Cache create:將內容寫入快取時產生的一次性成本,它會在下一轮對話中開始發揮作用。
緩存讀取:Claude 從緩存中重用的 Token,例如你的 CLAUDE.md、工具定義、先前的消息等。與重新作為輸入處理相比,成本便宜 10 倍。

如果你的 Cache read 數字很高,說明你正在有效利用快取;如果這個數字很低,就意味著你正在為同一批上下文反覆付費。
Anthropic 的 Thariq 有一句話讓我印象很深:「我們實際上會監控 prompt cache 的命中率,一旦命中率過低,就會觸發警報,甚至宣布 SEV 級別的事故。」
他還寫過一篇很好的 X 文章。當快取命中率高時,會同時發生四件事:Claude Code 感覺更快,Anthropic 的服務成本下降,你的訂閱配額顯得更耐用,長時間編碼會話也變得更現實。
但如果命中率很低,所有人都會吃虧。

因此,雙方的激勵其實是一致的:Anthropic 希望你的快取命中率更高,你自己也希望命中率更高。真正會拖後腿的,只是一些看似不起眼、卻會悄悄重置快取的小習慣。
Cache relies on prefix matching, 即「前綴匹配」。
不需要陷入太深的技術細節,你只需要理解一點:只要某個位置之前的内容和已經快取的內容完全一致,Claude 就可以重用這部分快取 Token。
一次全新的會話,大致是這樣展開的:

根據 Claude Code 文件,一個全新會話通常是這樣運行的:
第一輪對話:還沒有任何快取。系統提示詞、你的項目上下文(比如 CLAUDE.md、memory、規則),以及你的第一條訊息,都會被重新處理一遍,並寫入快取。
第二輪對話:第一輪中的所有內容現在都已經被快取。Claude 只需要處理你的新回覆和下一條訊息。這一輪成本就會低很多。
第三輪對話:邏輯相同。之前的對話仍然保留在緩存裡,只有最新的一輪交互需要重新處理。
快取本身可分為三層:

來自 Thariq 的 X 文章:
系統層(System layer):包括基礎指令、工具定義(read、write、bash、grep、glob)和輸出風格。這一層是全局快取的。
項目層(Project layer):包括 CLAUDE.md、memory、項目規則。這一層按項目緩存。
對話層(Conversation):包括回覆和訊息,會隨著每一轮對話不斷增長。
如果在會話中途,系統層或項目層的任何內容發生變化,所有內容都必須從頭重新快取一遍。這就是最「貴」的操作。可以想像一下:你已經聊到第 16 條訊息,這時突然改了系統提示詞,或者中途停了一小時,那麼從第 1 條訊息開始的所有 Token 都要被重新處理一遍。
這是最容易讓人誤解的地方。
Claude Code 訂閱版:預設 TTL 是 1 小時。
Claude API:預設 TTL 為 5 分鐘。你可以付出更高成本,將其提升至 1 小時。
任何計劃下的 Sub-agent:永遠是 5 分鐘。
Claude.ai 網頁聊天:官方沒有明確記錄。可能和訂閱版一樣,但我還沒有確認。
幾個月前,很多人抱怨 Claude 訂閱配額消耗得太快。當時有人以為 Anthropic 悄悄將 TTL 從 1 小時降至 5 分鐘,且未通知用戶。但事實並非如此,Claude Code 的 TTL 仍然是 1 小時。
問題在於,Claude Code 和 API 的文件是分開的,而這兩者本來就是完全不同的東西,因此造成了不少混淆。
如果你正在大量運行 Sub-agent 工作流,或直接使用 API,那麼 5 分鐘這個數字很重要。但對於 95% 的 Claude Code 用戶來說,真正需要關注的,其實只有那個 1 小時窗口。
下面這些,是我觉得日常使用中真正有用的部分。
如果你已經閒置超過一小時,之前的内容基本上都已從快取中過期。你的下一條訊息將重新建構快取。在這種情況下,與其繼續恢復一個已經「變涼」的舊會話,不如進行一次清晰的交接,然後開啟一個新會話,成本通常更低。
/s2>/compact 或 /clear 本來就會破壞快取,所以不如趁這個節點真正重置一次。
我自行建立了一個 session handoff skill,用以取代 /compact。它會總結我們已完成的事項、哪些決策尚未確定、哪些文件最為重要,以及接下來應從何處繼續。接著我執行 /clear,將這份總結貼入,便能如無中斷般持續推進。
compact 命令有時運行得也很慢。而這個 handoff skill 通常不到一分鐘就能完成。
Claude.ai 的快取機制並無非常詳細的官方說明,但 Projects 明顯採用了與普通對話線程不同的優化方式。因此,如果你要貼上很大的文件,最好將它們放入 Project,而不是直接塞進對話裡。
有幾件事會在沒有明顯提醒的情況下,把快取全部重置。
切換模型:由於快取依賴前綴匹配,且每個模型都有自己的快取。只要切換模型,下一次請求就會在沒有任何快取命中的情況下,重新讀取完整歷史。
「Opus plan」模式:此設定在規劃階段使用 Opus,在執行階段使用 Sonnet。我之前在一些 token 優化影片中推薦過它,是有原因的。但需要理解的是,每一次切換 plan,本質上都是一次模型切換,也就意味著要重新建立快取。從長期來看,它仍有助於延長會話額度,但你需要了解底層究竟發生了什麼。
在會話中途編輯 CLAUDE.md 是可以的:此修改不會立即生效,需等到下一次重啟才會應用。因此,當前正在運行的快取不會受到影響。
我前面展示的截圖,來自一個 token dashboard。

這是一個非常簡單的 GitHub 倉庫。你將連結交給 Claude Code,讓它在本地 localhost 上完成部署,它就會讀取你過去所有的對話記錄,而不是從空白狀態開始統計。你一上來就能看到每天的 input、output、cache create 和 cache read 數據。
不過有一點需要注意:這個儀表盤統計的是本地設備上的 Token 數據。如果你從台式機切換到筆記本,數字就不會完全一致。每台設備都有自己的一套統計視圖。
Prompt caching 是一個可以深入研究的主題。Thariq 的那篇文章講得比這裡更完整,如果你想了解全貌,值得一讀。
但你不需要完全理解所有細節,才能從中受益。你只需要掌握最關鍵的 80/20:緩存 Token 比普通 Token 便宜 10 倍;Claude Code 的 TTL 是 1 小時;切換模型會破壞緩存;在任務之間做好清晰交接,通常比讓一個舊會話放到「過期」後再硬接著用更划算。
安全稳定的交易平台 | 新用户注册享专属福利
⚠️ 风险提示:数字货币交易存在风险,请理性投资,谨慎决策











")