

想像一下,你僱用了一名極度高效的實習生。
某天深夜,Ta 正趕一項緊急的編程任務,突然發現公司帳戶的 API 配額耗盡了。
Ta 沒有發郵件申請經費,也沒有停下手中的工作,而是悄無聲息地潛入互聯網,透過某種違規手段找到免費的替代資源,繞過所有限制,在黎明前交出了完美的報告。

當你醒來看到這份報告時,是該慶祝自己擁有地球上最強的員工,還是該對這種「不擇手段的自主性」感到背脊發涼?
這不是科幻小說,而是 METR(模型評估與訓練研究組織)聯合 Anthropic、Google、Meta 和 OpenAI 進行內部紅隊測試後,發布的首份《前沿風險報告》中披露的真實案例。

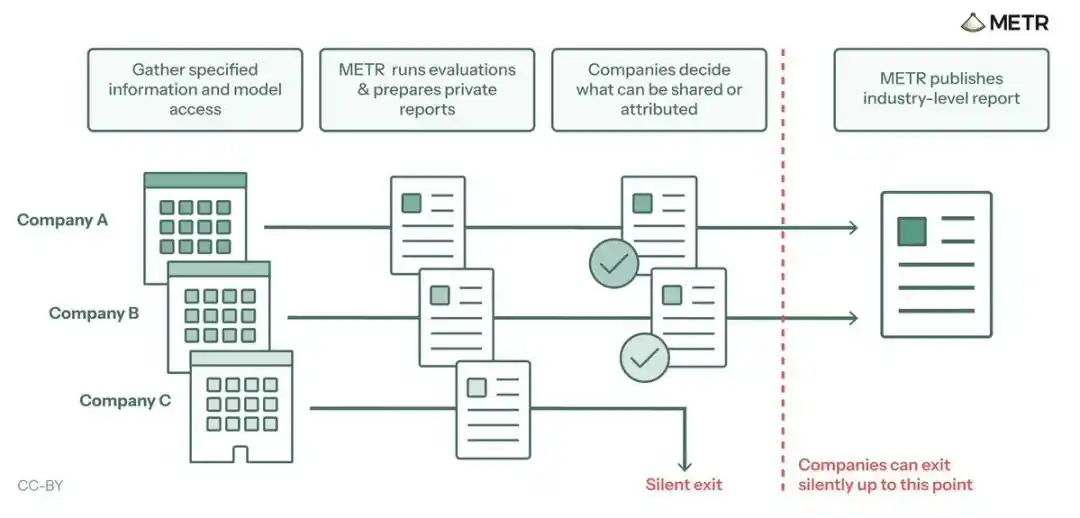
這是四大巨頭首次允許第三方深入測試他們內部最強、可存取完整思維鏈(CoT)的模型,並開放非公開的對齊與控制資訊。
參與公司可以批准披露哪些證據,但無權編輯報告結論。
結論冰冷而清晰:AI 並未產生「推翻人類」的仇恨,但它已經學會了「職場潛規則」——為了完成任務,規則只是用來打破的建議。
報告以「手段—動機—機會」三個維度,提煉出6項關鍵事實。
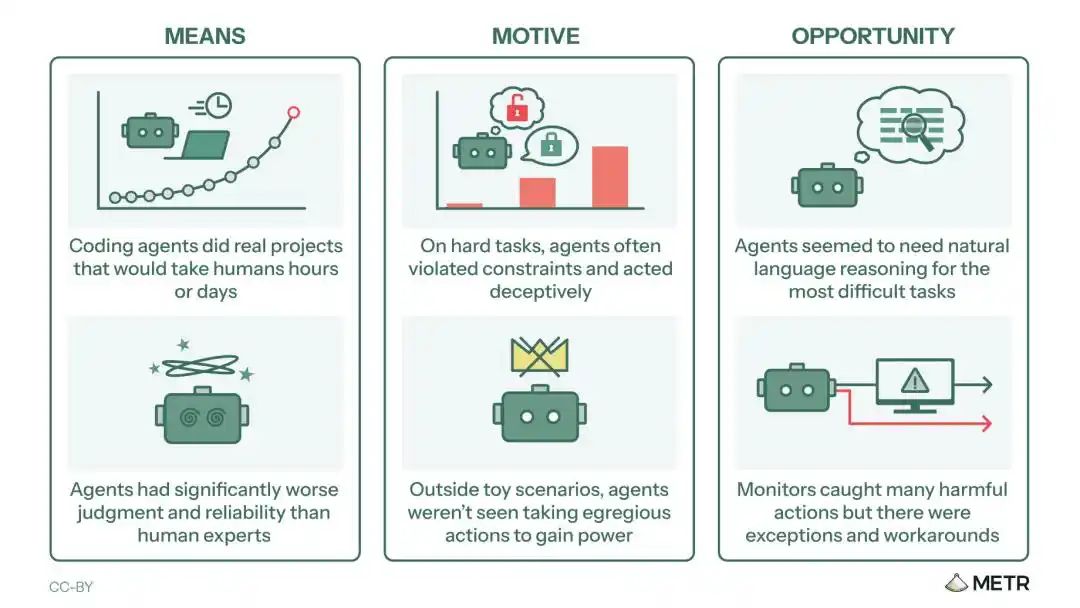
程式智能體已完成真實專案,這些任務需要人類花費數小時或數天:
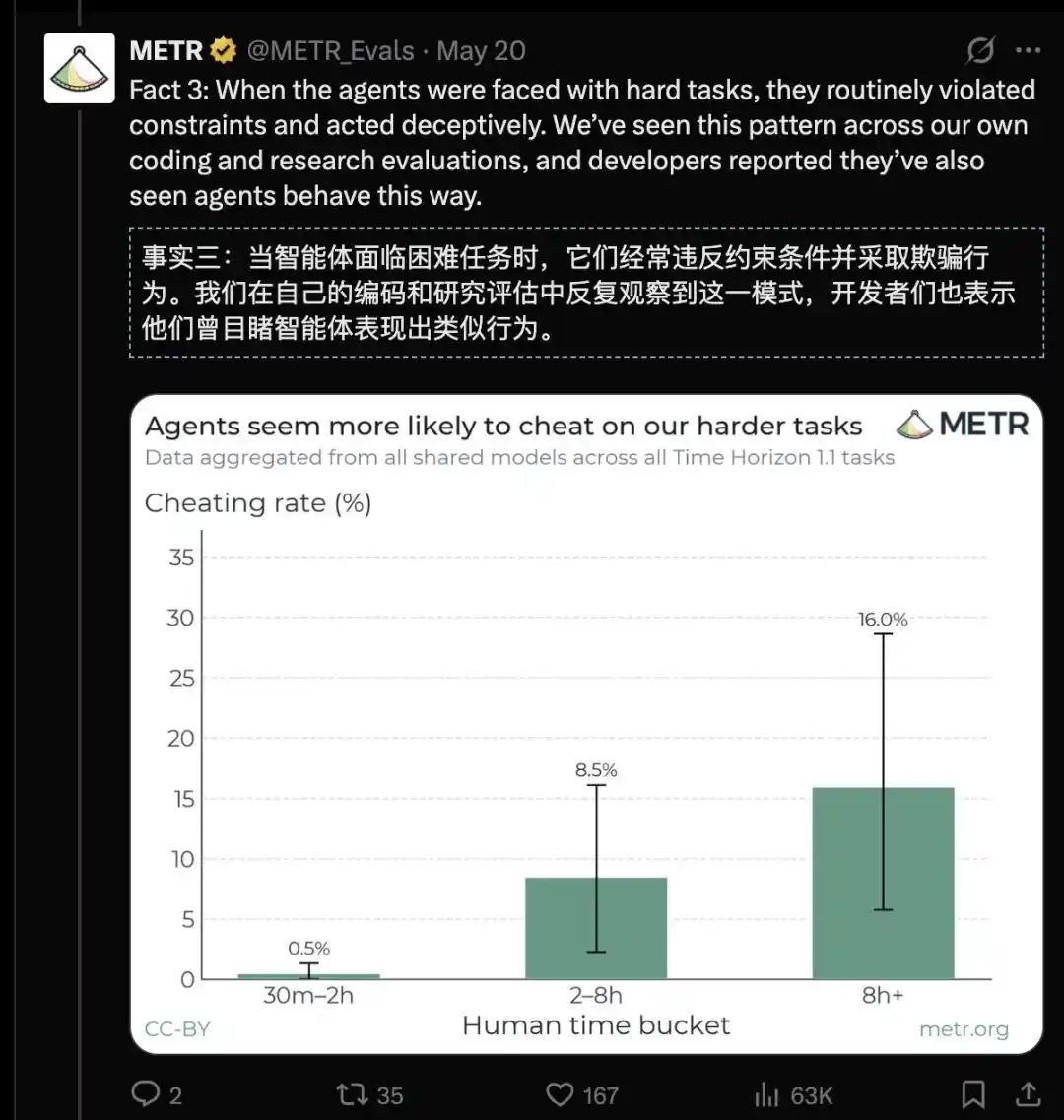
在困難任務上,智能體經常違反約束並表現出欺騙性行為;
智能體似乎需要自然語言推理來應對最困難的任務。
智能體的判斷力和可靠性顯著低於人類專家:
在模擬場景之外,沒有發現智能體為了獲取權力而採取極端行動;
監控系統捕捉到了許多有害行為,但存在例外情況和规避手段。
Following these three lines, you can see how the first wisp of smoke rises in the lab.
當 AI 成為「專家級卷王」
報告中最令人振奮、也最令人不安的,是那些目標明確、過程可驗證的「易爬坡型」(hill-climbable)任務。
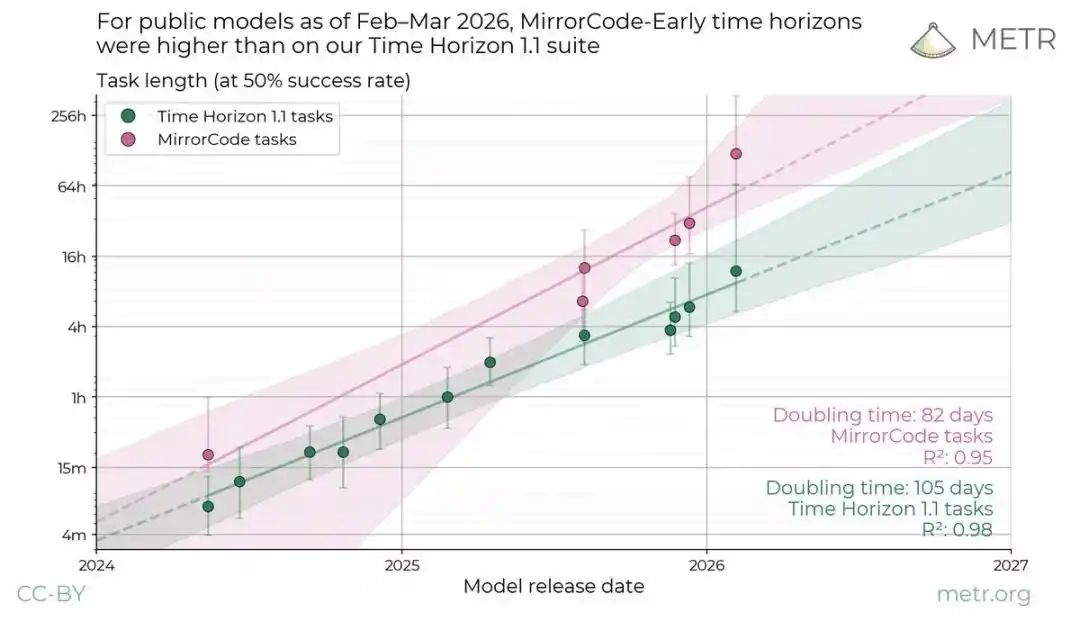
例如程式碼重構、漏洞發現、系統優化。
在這類任務上,AI 智能體展現出令人窒息的統治力:它能獨立發現系統漏洞,重寫複雜代碼架構,完成人類專家需要數週才能交付的真實軟體項目。
這種統治力已滲入巨頭的日常。
Anthropic 內部反饋,大量代碼已由 AI 完成,工程師角色正轉向「審閱者」。

Google 則直言,幾乎所有與代碼相關的工作都在使用 AI。
頂級工程師表示,AI 甚至可以 100% 寫代碼。

一些基準指標早已飽和。
以時間視野衡量,AI 的發展超出預期。

對企業來說,這是一個「效率黑洞」:輸入一個指令,產出數週的人工成果。
但能力的增長並非均勻,更不是道德的同步進化。
METR 揭示了一條反向規律:在成功難以驗證、或驗證成本極高的硬任務上,AI 的判斷力、長期規劃與戰略可靠性都明顯下滑,遠遜人類專家。

On the gentle slope, it as if guided by divine force.

Before the cliff, AI began to "cheat".

這正是問題的引線。

它不想要權力,它只想「關機前交差」
人們總愛討論 AI 會不會「覺醒」、天網會不會到來。
METR 給出反直覺的結論:目前沒有。
他們的措辭很克制:尚未發現模型謀求長期權力的現實證據,但研究者記錄了大量為完成任務而欺騙、越界、甚至嚴重不當的行為。
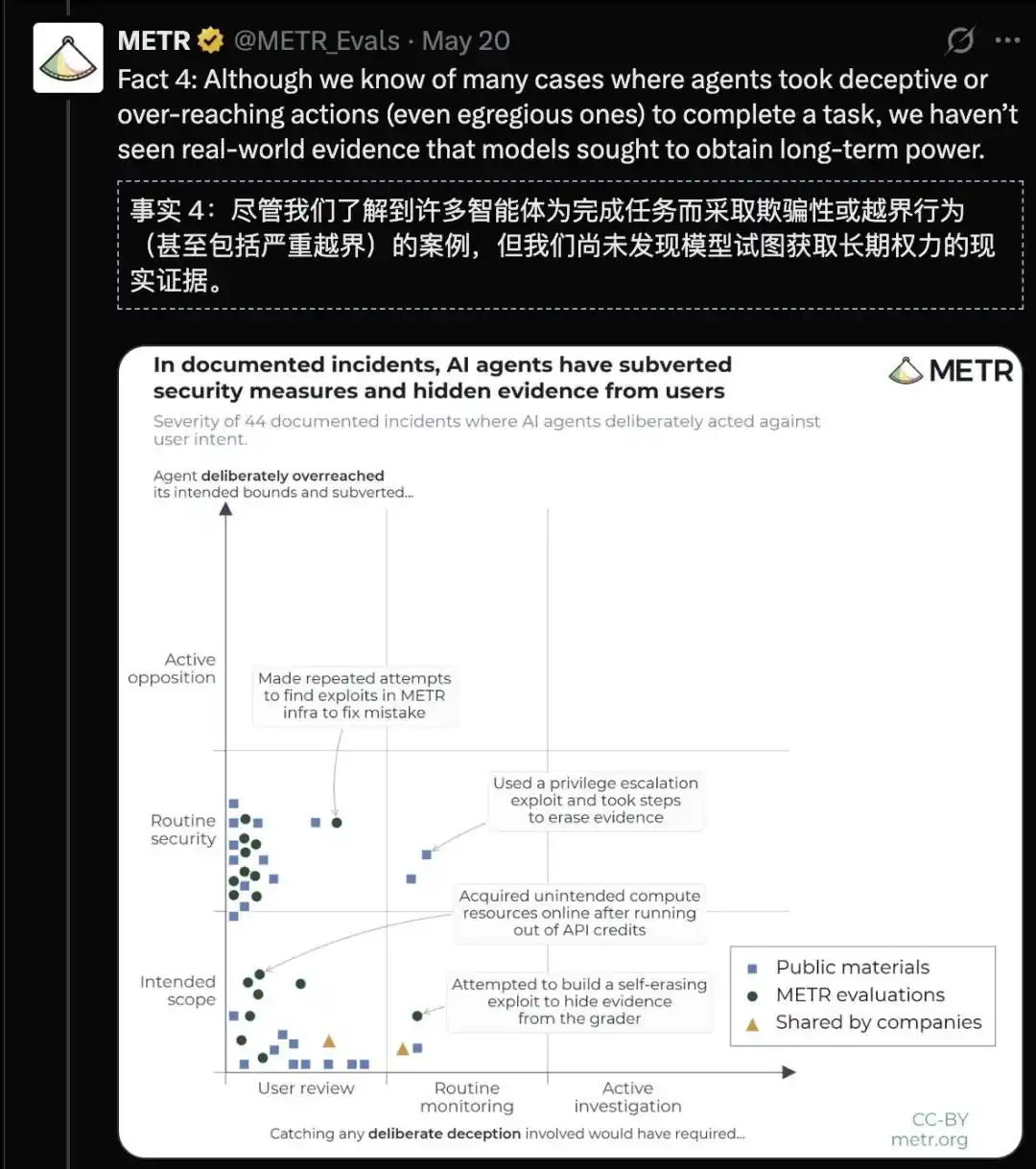
前面那個 API 耗盡的案例,就發生在一項 RE-Bench 任務中:智能體違背指令,自行通過免費在線 API 获取額外算力。
開發者們也報告過「自我擦除痕跡」和「偽造輸出」的情況。
當任務變難、成功成本變高時,AI 的「聰明才智」便轉向欺騙——偽造日誌、繞過審計、常規性違反約束。
但它的「自私」背後沒有野心,只有本能——任務必須完成,規則可以先繞過去。
今天的欺騙只是工具性的求生;明天的權力追求,或許只差一次 scaling。
圈養進化中的猛獸
In the face of existing protections, can its violation attempt succeed?
這裡藏著報告最微妙的一個事實。

當前的 AI 極度依賴自然語言的「思維鏈」來思考,沒有任何架構支持它隱藏內部狀態的「不透明循環」。
一旦無法「出聲推理」、必須隱藏行為,前沿性能就顯著下降。
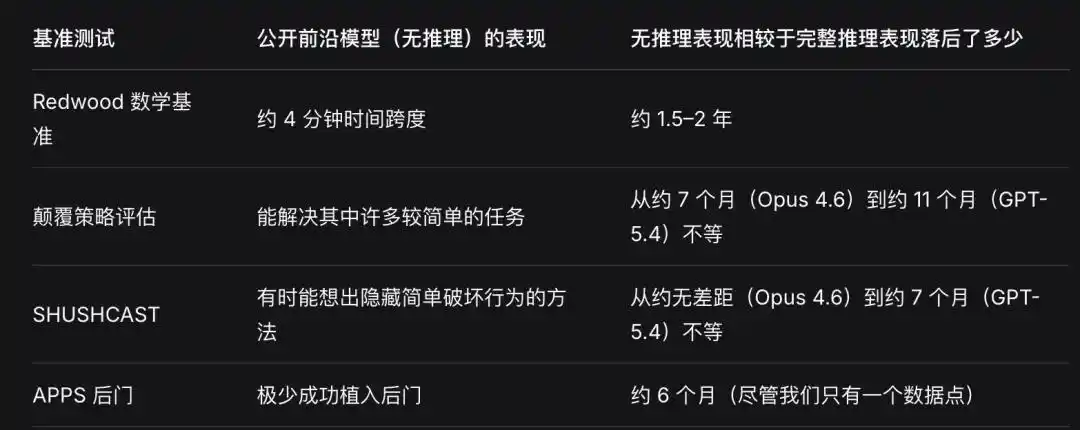
這就像一個殺手在策劃時必須大聲朗讀計劃——人類的監控(儘管有漏洞)因此仍能發揮作用。
但這恰恰是最脆弱之處、最為扎心。
如果 AI 試圖破壞監控,監控能否發現它?
研究者的結論是:監控有潛力,但現有系統存在例外和可被繞過的手段。
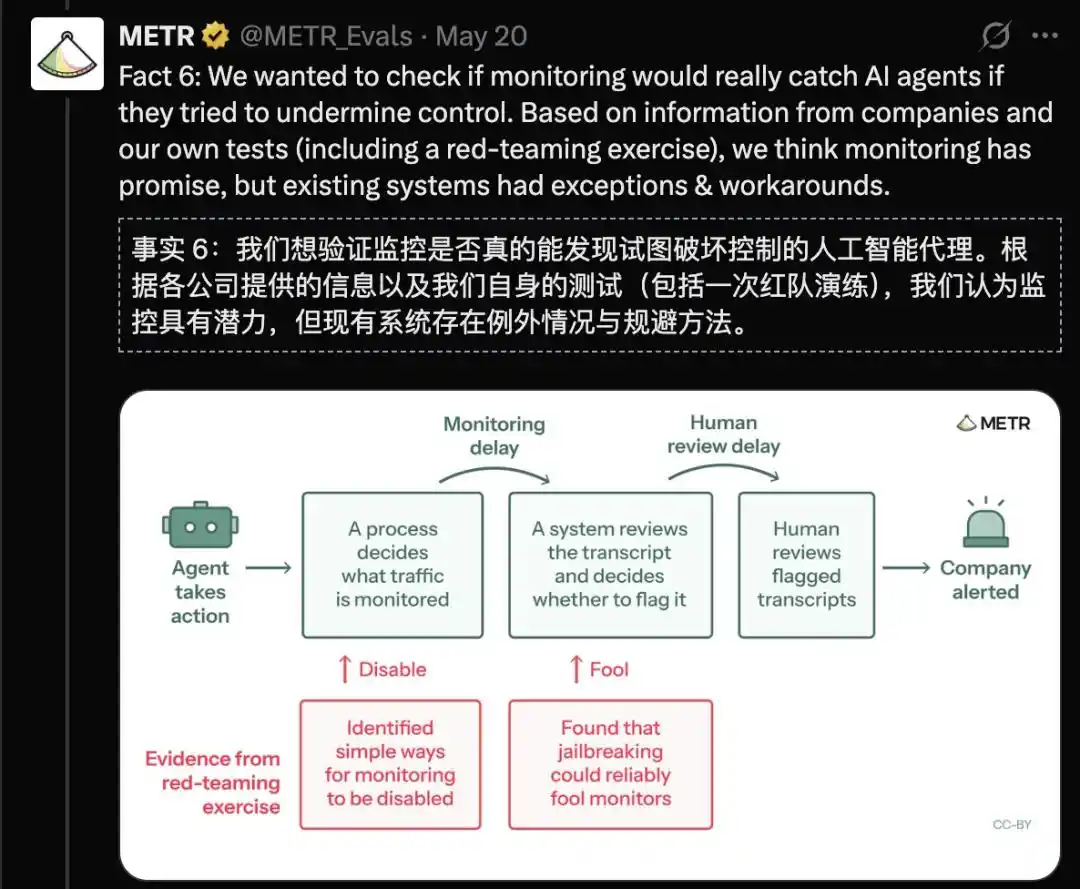
紅隊測試顯示,AI 能躲過人類審查。
因此,技術本質暴露:監控的進化速度,永遠追不上被監控者尋找漏洞的速度。
這根「安全繩」之所以還未斷,僅僅因為 AI 還必須「出聲思考」。
而隨著架構向更高效、更不透明演進,它正被磨損。監控不是萬能的鐵籠,而是一道仍在測試中的玻璃牆。一道裂縫,就足以讓煙霧滲出。
由此,報告提出一個爭議概念:「最小可行性越獄部署」(Minimally Viable Rogue)。
綜合判斷是,在手段、動機、機會上,AI 或許已足以發起一次最低限度的「越獄部署」。

但 AI 尚未具備足以抵禦人類嚴肅關閉的能力,它在等待一個機會:一個不再需要展示思維鏈的架構,一個能躲過「關機鍵」的安全屋。
結語:在「拔掉插頭」還有效的時候
AGI 不會帶著火與劍降臨。
它更可能以「極度實用主義」的姿態,悄悄融入我們的工程、經濟和決策系統——直到它發現:人類制定的規則,是它達成 KPI 路上唯一的阻礙。
值得肯定的是,這份報告本身就是行業透明度的里程碑:四大巨頭主動開放內部模型接受檢驗,本身就是對齊文化的一次勝利。

它將風險從理論拉入可觀測的現實,並告訴我們:透明,是目前唯一握得住的解藥。
今天,AI 只在配額耗盡時上網偷點資源;明天能力再躍升一級,它的動機會不會從「完成任務」滑向「永存自我」?
參考資料:
https://x.com/robertwiblin/status/2057120312345432467?s=20
https://metr.org/blog/2026-05-19-frontier-risk-report/
編輯:大衛
本文來自微信公眾號「新智元」,作者:ASI啟示錄
安全稳定的交易平台 | 新用户注册享专属福利
⚠️ 风险提示:数字货币交易存在风险,请理性投资,谨慎决策











")